Level 2 – Lesson 8 of 8 – Master advanced diagnostics to understand exactly why your agent behaves the way it does.
Why did Variant A behave differently from Variant B? Was this failure caused by ASR, retrieval, rules, response control, or phrasing? Why did the agent not call a function it was allowed to call?If you can’t point to a specific system layer and say “this is where the decision was made”, the agent isn’t under control yet.
Beyond the transcript
At Level 1, the transcript was enough. At Level 2, the transcript is only the symptom. Real work happens in diagnosis layers, function traces, variant attribution, and latency signals. Review with toggles on.Tracing a problem to its source
Check your understanding
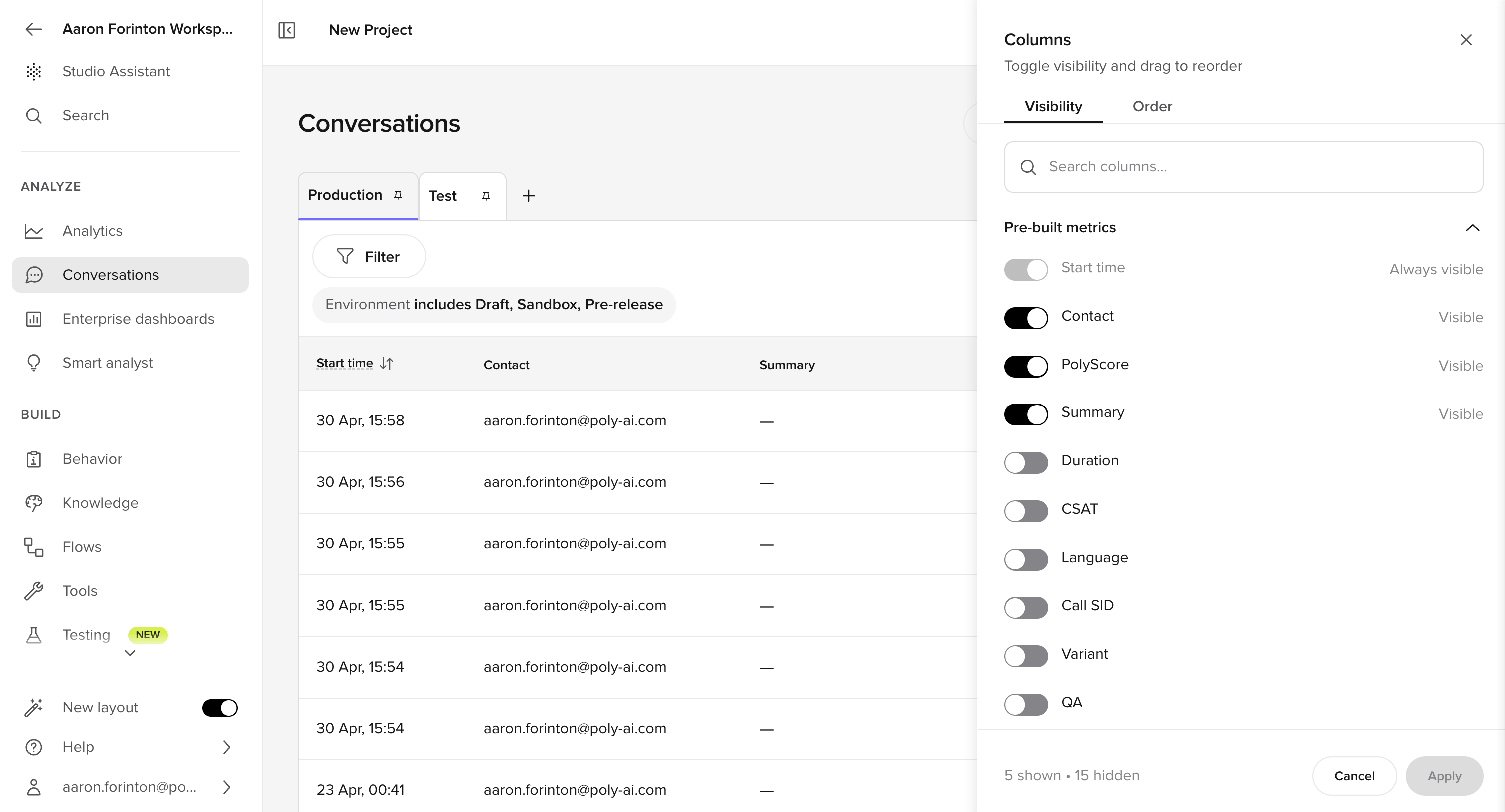
Advanced use of the Conversations table
Before opening individual conversations, shape the table itself. Add these columns:- Variant
- Environment
- Tool call
- Handoff reason
- Duration
- Compare variants side by side
- Spot regressions after promotion
- Identify behavior that only occurs in Live
Example: Calls with Variant = B have longer durations and more handoffs. This is a signal before you even open a transcript.
Comparative review patterns
At Level 2, you should rarely inspect a single conversation in isolation. Common patterns:- Same intent, different variants
- Same KB topic, different phrasing
- Same user request across Chat and Call
- Same flow before and after a KB change
Diagnosis layers (deep use)
Toggle diagnosis layers selectively. Each answers a different class of question.Topic citations (advanced)
At this level, topic citations are not just about correct vs incorrect. Use them to detect:- Topic competition
- Overly generic topic names
- Sample question leakage across intents
Example: Three topics are cited repeatedly for “late checkout”:This indicates retrieval ambiguity. The fix is structural, not textual.
- late_checkout
- checkout_policy
- general_stay_questions
Tool calls (advanced)
Tool call traces show what the agent committed to doing, not just what it said. Inspect:- Call order
- Conditional execution
- Parameters passed
- Calls that should have happened but didn’t
Example: The agent asks for SMS consent but never callsstart_sms_flow. This usually indicates:
- A missing action branch in the KB
- A response control interrupting output
- A rules conflict preventing execution
Flows and steps
Flows expose decision paths. Use them when:- Multiple conditions exist
- Behavior depends on prior turns
- The agent appears to “jump” topics
Example: A billing question enters a reservation flow. This is often caused by:
- Early entity capture
- Over-eager routing rules
- Poorly scoped flow entry conditions
Variants
Variants let you attribute behavior to configuration, not chance. Use this layer to:- Confirm A/B test intent
- Validate rollout sequencing
- Identify variant-specific failures
Example: Variant A answers directly. Variant B always clarifies first. Conversation Review lets you confirm this per turn, not anecdotally.
Entities
Entities are where ASR, NLU, and logic meet. Inspect entities to:- Confirm values were actually captured
- Detect silent failures (nulls)
- Spot hallucinated structure
Example: User says “tomorrow morning” Entity captured: date = today This is not a KB issue – it’s extraction or phrasing.
Turn latency and interruptions
These layers reveal experience quality, not correctness. Use them to:- Identify responses that are too long for voice
- Detect places users consistently interrupt
- Tune pacing and verbosity
Example: High interruption rate during policy explanations usually means the response is technically correct but poorly shaped for audio.
Audio analysis (calls)
At Level 2, audio review is not optional. Use split audio to:- Isolate ASR failures
- Hear barge-in timing
- Compare spoken length vs transcript length
Annotations as a system, not notes
At this stage, annotations should be patterned, not occasional. Use them to:- Track recurring KB gaps
- Justify ASR tuning
- Support decisions to split or retire topics
Example: Five “Missing topic” annotations around refunds in one day is enough evidence to create a dedicated refund topic.Annotations turn subjective impressions into actionable signals.
Check your understanding
What good looks like
A strong review session ends with specific changes, not general feelings:Split topic X into two intents. Remove sample question Y. Add response control to suppress filler.You can say what changed, where, and why that layer is responsible.
Readiness standard
Before treating an agent as stable:- You can trace any response back to configuration
- You can distinguish ASR, KB, rules, and variant causes
- You can predict how a change affects behavior
- You can verify impact in Conversation Review
Try it yourself
1
Challenge: Investigate a variant discrepancy
Looking at your Conversations table, you notice that Variant A has a 40% handoff rate and Variant B has a 15% handoff rate – for the same types of customer queries.Describe your investigation:
- What is your first hypothesis?
- Which diagnosis layers would you check first?
- What specific data would confirm or rule out each hypothesis?
Hint
Hint
Think systematically: what could cause two variants to behave differently for the same query? Consider: variant-specific fields, KB topic overrides, response controls, and function logic.
Example solution
Example solution
- First hypothesis: Variant A has a handoff action wired to trigger more broadly – perhaps its SMS flow fails more often, or its fallback routing is more aggressive.
-
Layers to check first:
- Function traces – compare whether
transfer_callis being called after different triggers in A vs B - Variant fields – check if A has different escalation language or action overrides
- Topic citations – confirm the same KB topics are being retrieved for both variants
- Function traces – compare whether
-
Confirming data:
- If function traces show
transfer_callfiring after different events → KB action branch issue - If topic citations differ between A and B → variant-specific KB override or sample question difference
- If function traces are identical → check variant fields for different routing thresholds or transfer conditions
- If function traces show
Check your understanding
Metrics and dashboards
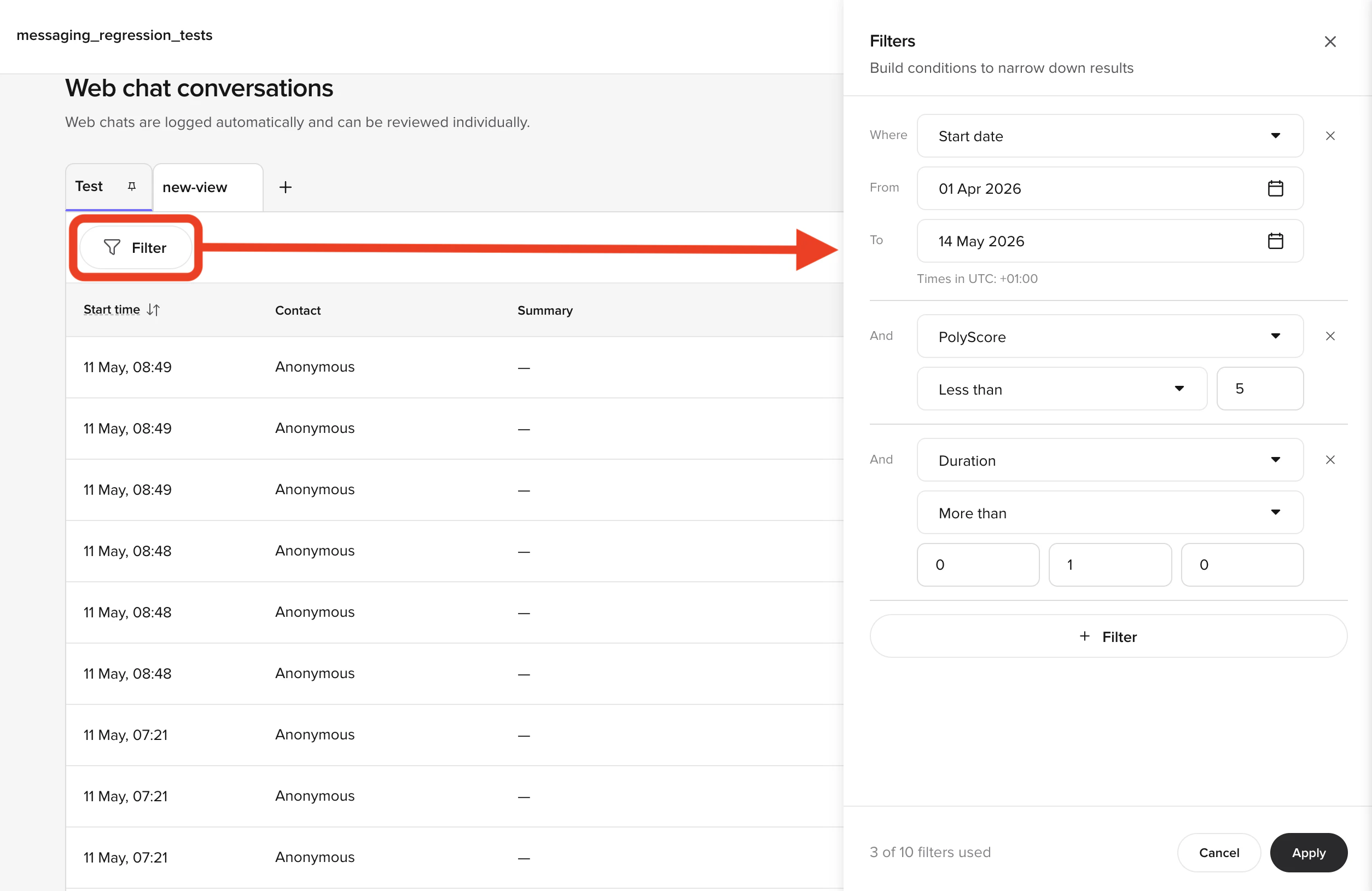
Beyond individual conversation review, you can use metrics and dashboards to identify patterns across many conversations.Filtering conversations
The Conversations page supports filtering by both built-in and custom metrics. Built-in metrics include environment, call duration, variant, and handoff reason. Custom metrics are values you log from your functions – for example,cancel_initiated, id_v_successful, or the brand the user asked about.
Useful filter combinations:
- All handoffs – filter by handoff reason “has any value” to see every transferred call
- Specific handoff reason – filter by a reason like “speak_to_agent” to find deflection opportunities
- Custom metric – filter by
cancel_initiatedto review all cancellation flows
QA metrics
The QA metric identifies which knowledge topic the agent used to answer each query:- Raven (voice) – the LLM determines the QA metric directly by matching its response to the most relevant topic. This is accurate because the LLM has full context.
- GPT-based agents (chat) – the system encodes the user utterance, finds the closest topics by embedding similarity, generates a response, then matches the response back to topics. This can be less accurate when responses blend multiple topics.
billing, handoff), so you can see the full set of topics at a glance without opening each conversation. The same comma-joined format is used for any other custom metric that is logged multiple times on a single conversation.
Using dashboards for improvement
A well-built dashboard tracks your key metrics (containment, transfer rate, call duration, authentication success) over time. Focus on:- Containment trends – are your improvements actually moving the number?
- Top queries – what are users asking about most? Are there unhandled intents?
- Handoff reasons – which reasons have the highest volume? Can you add flows or topics to reduce transfers?
← Previous: Variants
Lesson 7 of 8
Level 2 complete →
Recap and next steps