Lesson 6 of 6 – Last step! You’ll learn how to look at real conversations and figure out whether your agent did the right thing – and what to fix if it didn’t.
What conversation review is for (level 1)
At this stage, use Conversation Review to answer simple but critical questions:Understanding
Did the agent understand the user?
Topic matching
Did it answer from the right Managed Topic?
Escalation
Did it escalate or hand off when expected?
Errors
Did anything obviously go wrong?
You are not tuning behavior yet. You are confirming that the basics work.
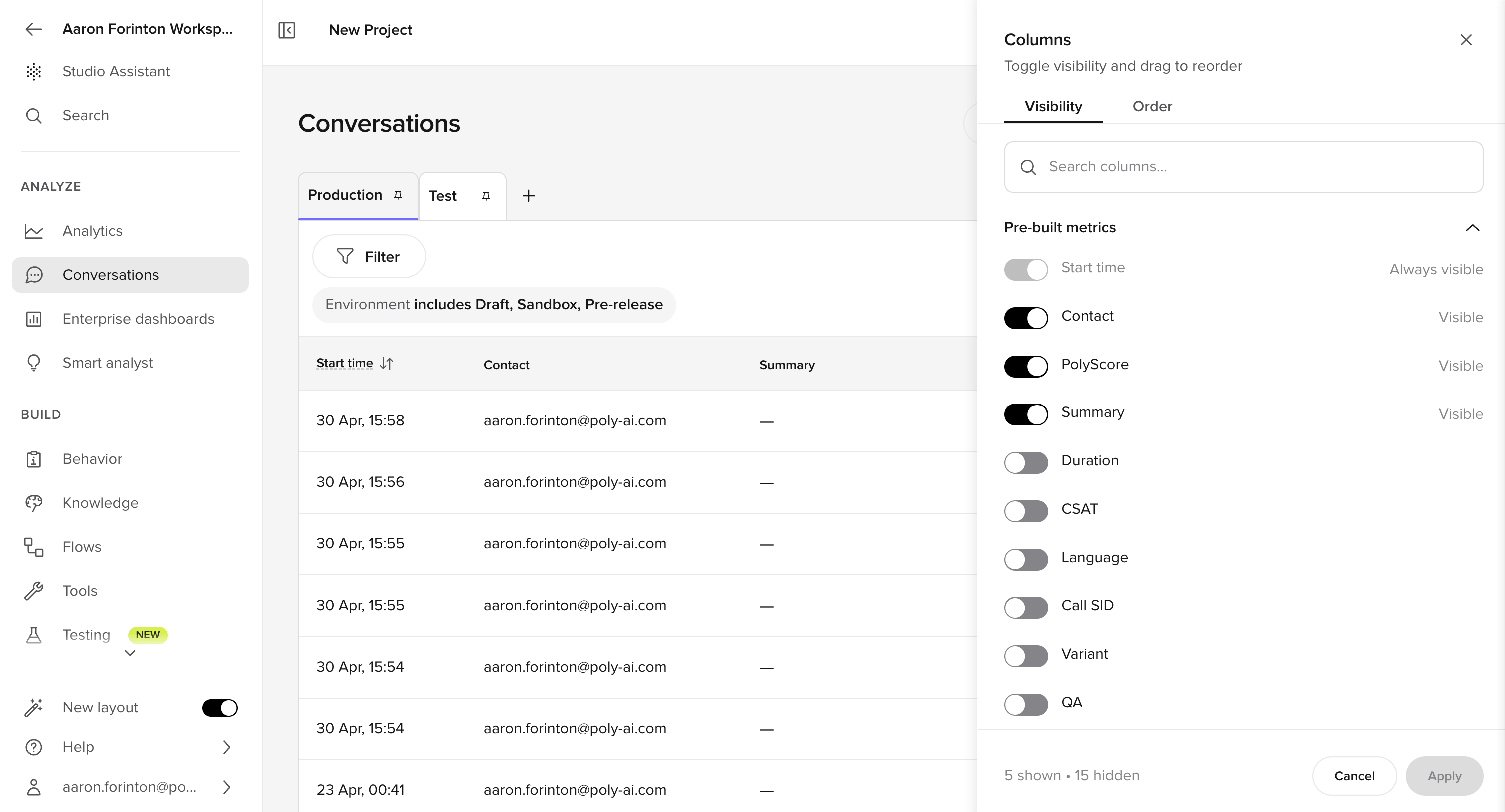
Starting in Conversations
Begin on the Conversations page. This table lists all interactions across Chat and Call. Focus on these columns:- Status: Live or Ended
- Summary: High-level intent label
- Start time: Helps align with test runs
- Contact: Phone number or user identifier
- Duration: Longer calls often signal confusion
- PolyScore (if enabled): Quick quality indicator
- Environment
- Variant
- Handoff reason
- Tool call
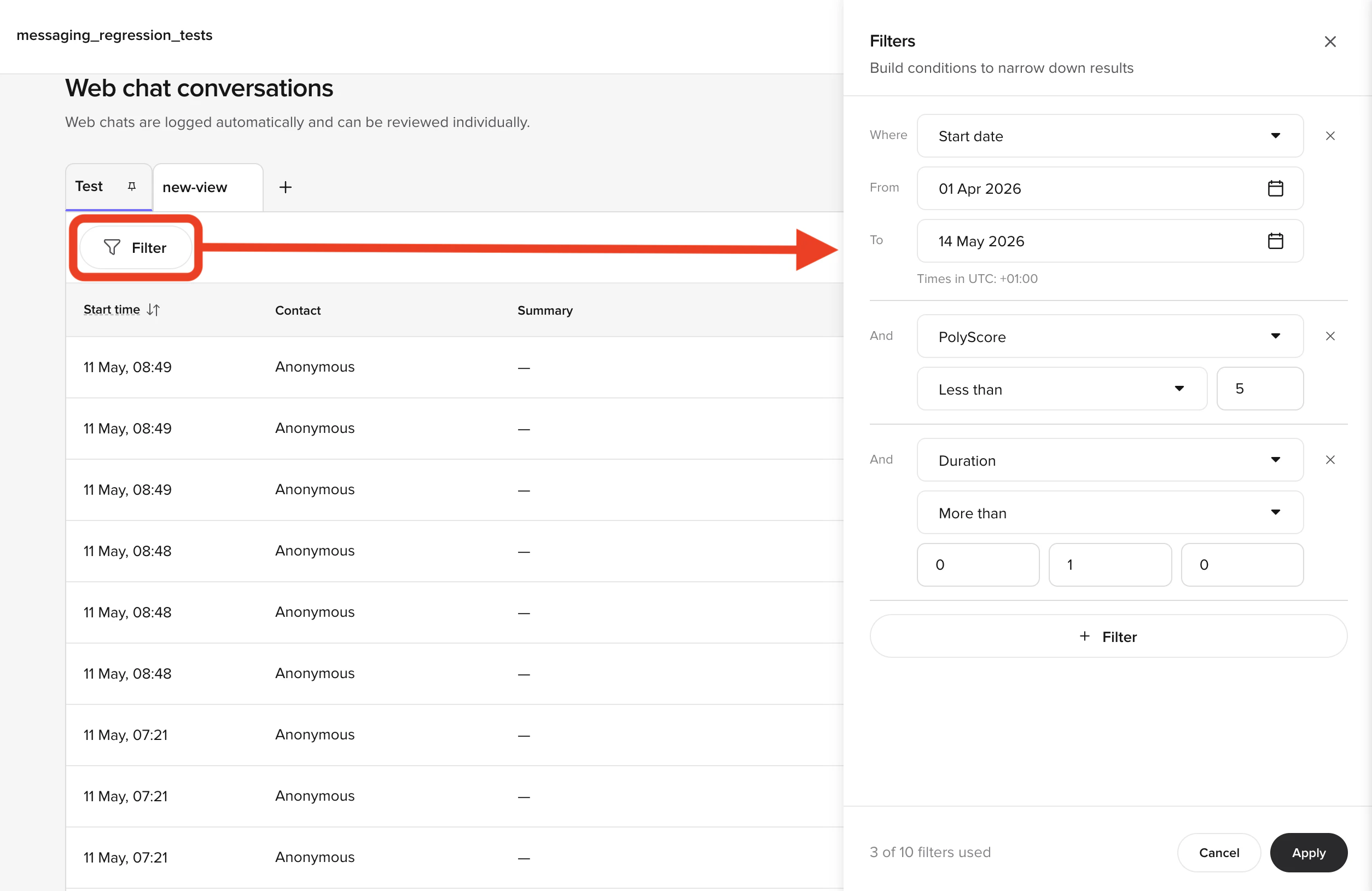
Filtering during testing
Use Filter to narrow your view. Common Level 1 filters:- Environment = Sandbox
- Start date = Today
- Duration > 60 seconds
- Status = Ended
Example: Filter to Sandbox + Duration > 90s to find conversations where the agent struggled.
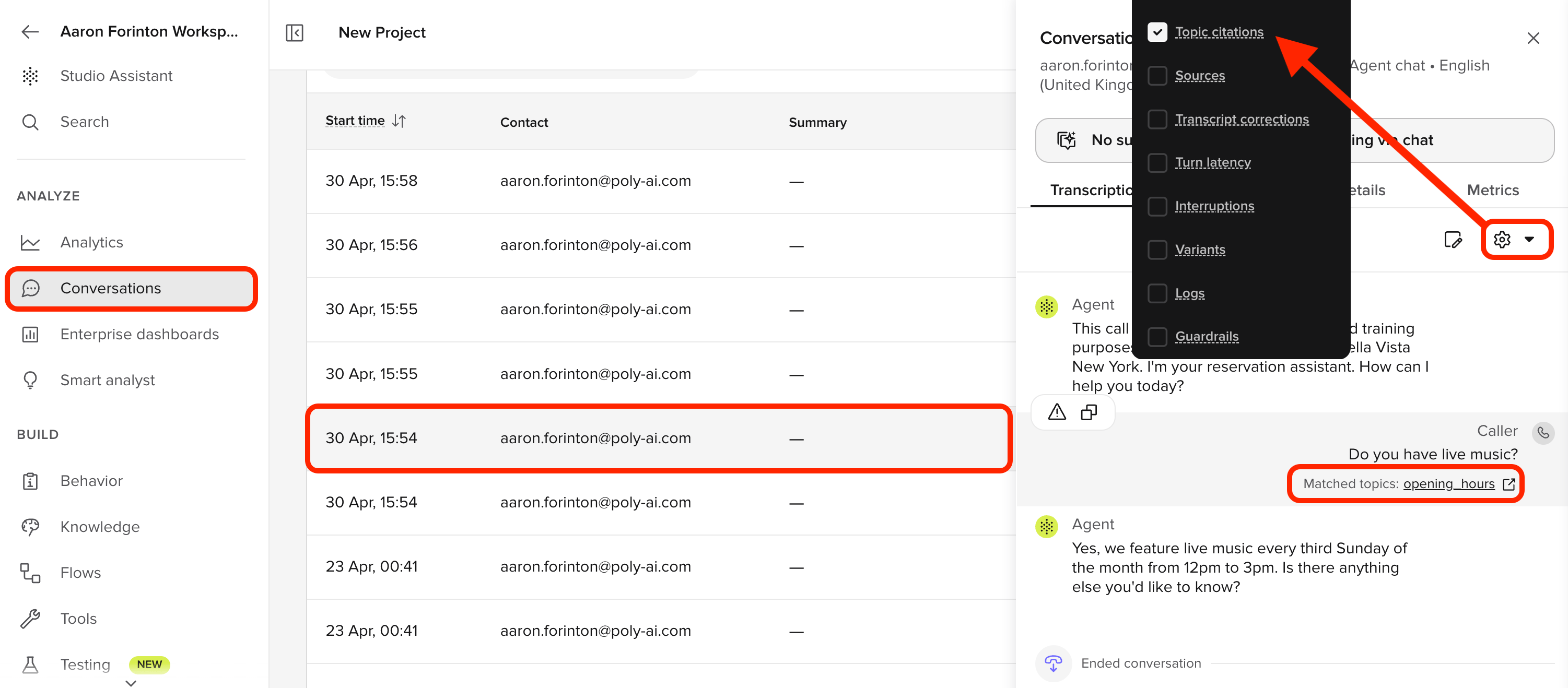
Opening a conversation
Clicking a row opens the Conversation Review side panel on the right. The header shows the contact, timestamp, channel type, and language, and the panel has four tabs:- Transcription — the turn-by-turn transcript, the Diagnosis toggle group, and (for voice) the audio waveform.
- Scores — PolyScore and CSAT badges with per-dimension breakdowns.
- Details — call info (environment, variant, duration), pre-built metrics, and links to latency visualization and data logs.
- Custom metrics — any custom metrics configured for your project.

Reading the transcript
The transcript shows the conversation turn by turn. For each turn, check:- What the user said (ASR text)
- How the agent responded
- Which Managed Topic was matched (shown beneath the turn)
Example:
User: “late checkout”
Matched topic: late_checkout_policy
This is the expected outcome. If the wrong topic appears, the issue is almost always in Managed Topic naming or sample questions.
Check your understanding
Matched topics
Matched topics are your primary signal at this level. Use them to confirm:- The correct topic was selected
- Similar topics are not competing
- The topic name reflects the intent clearly
Example:
The agent answers about billing, but the matched topic is general_help.
This indicates a Managed Topic design problem, not a phrasing issue.
Confirming context on the Details tab
Open the Details tab in the side panel to confirm you’re reviewing the right conversation. Check:- Environment (Sandbox vs Live)
- Channel (Web chat or Voice)
- Language and locale (also visible in the panel header)
- Duration
- Variant (if applicable)
Basic diagnosis toggles
At Level 1, you only need a small subset of diagnosis tools.Topic citations
Use this to confirm which KB topic was used for each response. If the agent answers correctly but cites the wrong topic, fix the KB before proceeding.Tool calls (preview)
Functions, SMS, and handoffs are covered in Level 2. At Level 1, you likely don’t have any functions yet. If your project does use them, this toggle shows whether actions fired – but you don’t need it for basic diagnosis.
Audio playback (Calls only)
For call channels, use audio playback to:- Confirm ASR quality
- Hear how long responses feel when spoken
- Check whether users interrupt the agent
Annotations
Annotations let you flag issues directly from the review page. At Level 1, use:- Wrong transcription → ASR problem
- Missing topic → KB gap
What good looks like
After a review session you can say:- The agent selected the correct KB topic
- Responses matched the questions
- Escalation was reasonable
- Any problems trace to KB or ASR
Check your understanding
Before level 2
- You can explain each response in plain terms
- You can identify KB vs ASR issues
- The agent behaves consistently in Sandbox
Try it yourself
1
Challenge: Diagnose a mismatch
A user asked “do you accept dogs?” and the matched topic in Conversation Review shows
general_help instead of pet_policy.Answer:- What is the most likely cause?
- How would you fix it?
- How would you verify the fix worked?
Hint
Hint
The agent responded but used the wrong topic. This is a retrieval problem, not an ASR problem – ASR transcribed the question correctly. Think about what drives topic selection.
Example solution
Example solution
- Most likely cause: The
pet_policytopic’s name is too vague or its sample questions don’t include “dogs”, “pets”, or “animals” – sogeneral_helpwas a closer match. - Fix: Rename the topic to
pet_policyif it isn’t already, and add sample questions like “do you accept dogs”, “are pets allowed”, “can I bring my cat”. Ensuregeneral_helpdoesn’t have overlapping sample questions. - Verify: In Chat, ask “do you accept dogs?” and check that the topic citation now shows
pet_policy. Test several phrasings and confirm the topic is consistent.
Check your understanding
Go deeper
The Analytics section covers conversations, diagnostics, and scoring in full detail:Conversation Review
Full reference for the review interface and all available tools
Annotations
How to flag and categorize issues you find during review
Diagnosis tools
Advanced diagnostic toggles – covered in detail in Level 2
← Previous: Environments & versions
Lesson 5 of 6
Level 1 complete →
You made it – recap and next steps